São Paulo DC Outage Post Incident Summary

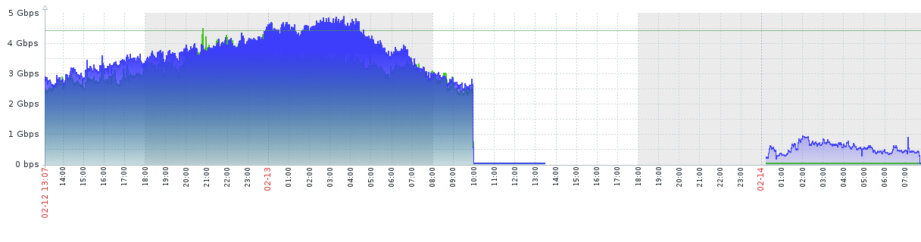
Most of the customers who have services within São Paulo DC experienced a network outage yesterday (February 13, 2020). It led to a complete blackout for some of the services. Firstly, please accept our apologies for any inconvenience caused and secondly I would like to give a full chronology of this incident we have faced. Then I will brief what steps we will take to prevent those types of outages.
Chronology
February 13, 2020 (Time zone GMT +0)
- 8:00 AM, we have received an alert from our monitoring center, that SAO location is down. After closer investigation, we have noticed that some of the racks were accessible where Bare-Metal Servers colocated.
- 9:00 AM, we have decided to reboot the core router.
- 11:00 AM, we have received a confirmation that the router reboot initiated.
- 5:00 PM, we gained access to the router and switches.
- 9:00 PM, we have diagnosed that router obtained the default settings and that switch ports lost its configuration. Some of the links we have successfully recovered, but some of them were not able to recover.
February 14, 2020 (Time zone GMT +0)
- 1:00 AM, we have made a decision not to waste any more time and decided to deploy the configuration on the alternative router we have onsite and investigate the problem with the current router later.
- 5:00 AM, all links were relocated to the alternative routers, but after some time, we have noticed that we have lost connectivity again with the DC.
- 6:00 AM, we have requested access to the routers again.
- 7:00 AM, we have gained access to the routers again. After that noticed that it was a misconfiguration in some of the configs.
- At 8:00 AM, all of the services restored.
- We are still carrying out the investigation and taking the necessary measures to prevent this from happening again.
Next Steps
Since the network infrastructure is running on Extreme Networks hardware (previous Brocade), we will swap all the network gear to Juniper. We had some incidents previously regarding the Extreme Networks gear, but since we have planned to do the upgrade in April, we will push this upgrade sooner. We can expect some downtimes during the updates, but they will be minimal, and in some cases, the upgrade will have no impact on the running services. Two cross-connects are between every rack for redundancy.
The next thing we will introduce is the KVM switch, which will allow us to connect to the infrastructure even if it’s down since we have spent a pretty large amount of time communicating between two continents fixing the problem. It allows connecting to the site straight away without any need of connecting the KVM over IP device with the help of remote hands to gain access to the network switches or routers. It will be a standard for all of our locations, but we will introduce this to the most critical ones first.
We will introduce the status page, where we will broadcast any updates and current statuses of the services. In other words, we will expose the monitoring of the services with the incident reports so that all communication and status updates would be in one place. We will introduce it by the end of next week or the beginning of the following.
Lastly, since we had a procedure to update the customers every two hours, we will reduce the time up to one hour if, in the unlikely event, something similar would happen.
Summary
Last year we had two major outages in São Paulo DC. It was due to the chopped CenturyLink fiber cable. We have learned from both of those outages what we need to fix. We have introduced additional upstream providers to blend the traffic better, and the same outage scenario will not happen. Last night’s outage showed us that we could rely on the systems that are proven to be working. That is why all of our locations have either MX960 or MX204 routers, which can handle the network correctly. The lesson learned, and at the same time, when our network engineering team is working on resuming services 100%, we in parallel organizing the shipment of the Juniper network gear to the DC.
We will update you once the status page is live, where we will notify all customers about the network equipment upgrade. Again, we sincerely apologize for the inconvenience caused, and we work hard to maintain quality assurance.
I want to thank and much appreciate, our network engineering team, our support team, and our head of infrastructure, Zilvinas Vaickus, for coordinating and fixing the issue.
Vincentas Grinius
CEO / Heficed
")

